新闻
你的位置:Kaiyun网页版·「中国」开云官方网站 登录入口 > 新闻 >
体育游戏app平台它们依然掌持了一般科研的广泛花式-Kaiyun网页版·「中国」开云官方网站 登录入口
发布日期:2024-12-12 05:07 点击次数:194
LLM 不错比科学家更准确地展望神经学的盘考恶果!
最近,来自伦敦大学学院、剑桥大学、牛津大学等机构的团队发布了一个神经学专用基准BrainBench,登上了 Nature 子刊《当然东说念主类行为(Nature human behavior)》。
恶果领路,历程该基准老师的 LLM 在展望神经科学恶果的准确度方面高达81.4%,远超东说念主类群众的 63%。
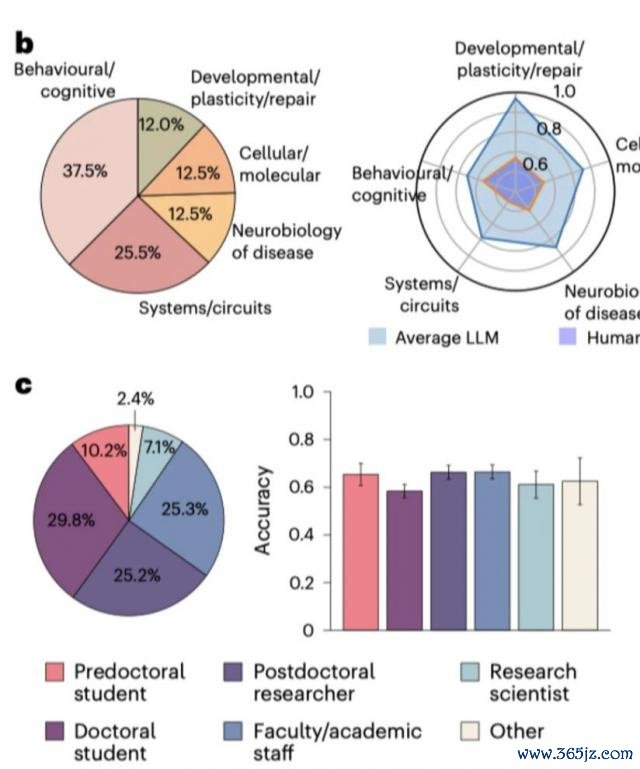
在神经学常见的 5 个子界限:行为 / 通晓、细胞 / 分子、系统 / 回路、神经疾病的神经生物学以及发育 / 塑性和成就中,LLM 的推崇也完整地点跳动了东说念主类群众。
更紧迫的是,这些模子被确认关于数据莫得赫然的记忆。
也即是说,它们依然掌持了一般科研的广泛花式,不错作念更多的前瞻性(Forward-looking)展望、展望未知的事物。
这立马激勉科研圈的围不雅。
多位教授和博士后博士后也暗意,以后就不错让 LLM 维护判断更多盘考的可行性了,nice!


LLM 展望才能全面独特东说念主类群众
让咱们先来望望论文的几个紧迫论断:
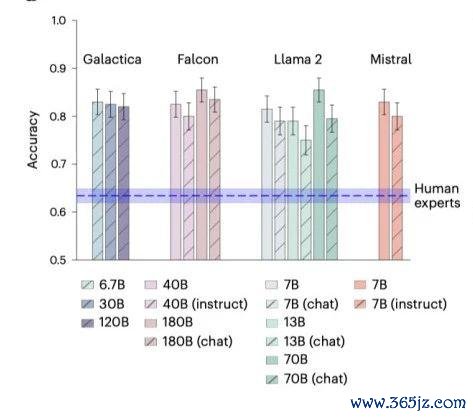
总体恶果:LLMs 在 BrainBench 上的平均准确率为 81.4%,而东说念主类群众的平均准确率 63.4%。LLMs 的推崇显赫优于东说念主类群众
子界限推崇:在神经科学的几个紧迫的子界限:行为 / 通晓、细胞 / 分子、系统 / 回路、神经疾病的神经生物学以及发育 / 塑性和成就中,LLMs 在每个子界限的推崇均优于东说念主类群众,绝顶是在行为通晓和系统 / 回路界限。
模子对比:较小的模子如 Llama2-7B 和 Mistral-7B 与较大的模子推崇很是,而聊天或请示优化模子的推崇不如其基础模子。
东说念主类群众的推崇:大无数东说念主类群众是博士学生、博士后盘考员或教职职工。当规则东说念主类反应为自我阐扬专科常识的最高 20% 时,准确率高潮到 66.2%,但仍低于 LLMS。
置信度校准:LLMs 和东说念主类群众的置信度齐校准雅致,高置信度的展望更有可能是正确的。
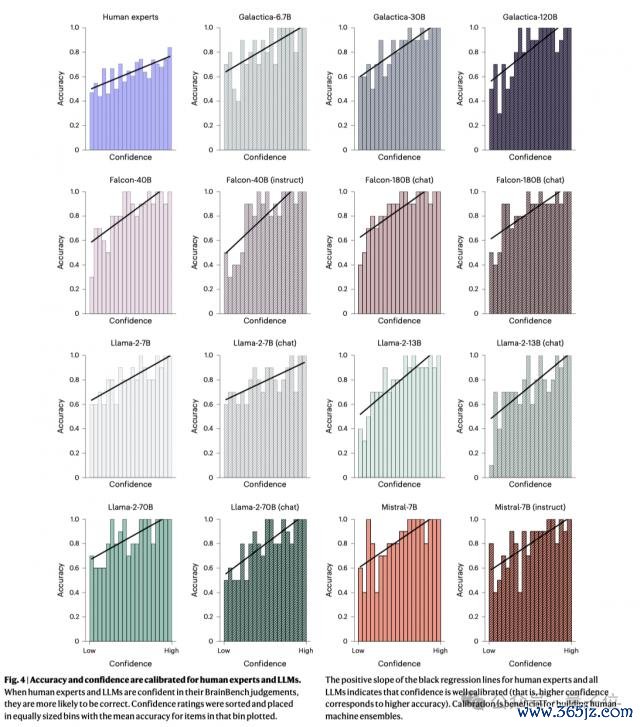
记忆评估:莫得迹象标明 LLMs 记忆了 BrainBench 技俩。使用 zlib 压缩率和困惑度比率的分析标明,LLMs 学习的是平凡的科学花式,而不是记忆老师数据。
全新神经学基准
本论文的一个紧迫孝敬,即是忽视了一个前瞻性的基准测试BrainBench,不错有益用于评估 LLM 在展望神经科学恶果方面的才能。
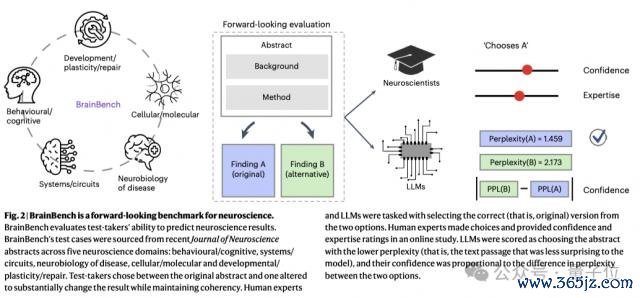
那么,具体是如何作念到的呢?
数据收罗
最初,团队愚弄 PubMed 赢得了 2002 年至 2022 年间 332807 篇神经科学盘考关联的纲领,从 PubMed Central Open Access Subset(PMC OAS)中索要了 123085 篇全文著作,揣测 13 亿个 tokens。
评估 LLM 和东说念主类群众
其次,在上头收罗的数据的基础上,团队为 BrainBench 创建了测试用例,主要通过修改论文纲领来杀青。
具体来说,每个测试用例包括两个版块的纲领:一个是原始版块,另一个是历程修改的版块。修改后的纲领会显赫蜕变盘考恶果,但保持合座连贯性。
测试者的任务是给与哪个版块包含实质的盘考恶果。
团队使用 Eleuther Al Language Model EvaluationHaress 框架,让 LLM 在两个版块的纲领之间进行给与,通过困惑度(perplexity)来掂量其偏好。困惑度越低,暗意模子越心爱该纲领。
对东说念主类群众行为的评估亦然在交流测试用例上进行给与,他们还需要提供自信度和专科常识评分。最终参与执行的神经科学群众有 171 名。
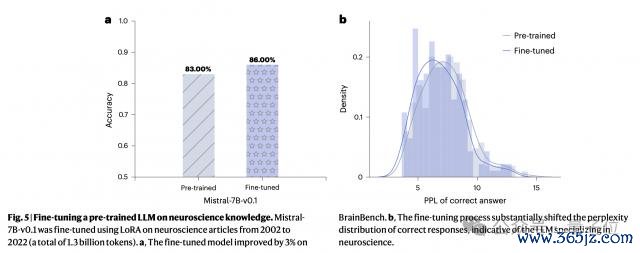
执行使用的 LLM 是历程预老师的 Mistral-7B-v0.1 模子。通过 LoRA 本事进行微调后,准确度还能再加多 3%。
评估 LLM 是否纯记忆
为了掂量 LLM 是否掌持了想维逻辑,团队还使用 zlib 压缩率和困惑度比率来评估 LLMs 是否记忆了老师数据。公式如下:
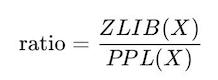
其中,ZLIB(X)暗意文本 X 的 zlib 压缩率,PPL(X)暗意文本 X 的困惑度。
部分盘考者觉得只可手脚扶助
这篇论文向咱们展示了神经科学盘考的一个新标的,粗略将来在前期探索的时刻,神经学群众齐不错借助 LLM 的力量进行初步的科研目的筛选,剔除一些在圭表、配景信息等方面存在赫然问题的计较等。
但同期也有好多盘考者对 LLM 的这个用法暗意了质疑。
有东说念主觉得执行才是科研最紧迫的部分,任何展望齐没什么必要:
还有盘考者觉得科研的要点可能在于精准的评释。

此外,也有网友指出执行中的测试圭表只磋商到了浅近的AB 假定训练,信得过盘收用还有好多触及到平均值 / 方差的情况。

合座来看,这个盘考关于神经学科研责任的发展还长短常有启发真理的,将来也有可能延伸到更多的学术盘考界限。
盘考东说念主员们如何看呢?
参考联接:
[ 1 ] https://www.nature.com/articles/s41562-024-02046-9#author-information
[ 2 ] https://github.com/braingpt-lovelab/BrainBench体育游戏app平台